Cleaning the data
There are features like the name of the passenger and the cabin which cannot be used for analysis directly.
Thus, I cleaned these features to make them more organized and informative.
Cabin feature has too many missing values and I can't imagine so many passengers boarding the ship with no cabin to stay in, meaning they must be true missing values. Let's drop the feature.
Name feature has some disorganized data. The actual names of passengers don't matter. The only meaningful information in the Name feature are the honorific of the passenger (Mr, Mrs, etc) which indicates gender and age range, and surname of the passenger (Braund, Cumings, etc) which indicates which passengers are from the same family.
-
Let's try to extract the honorifics of passengers by splitting Name on the first comma (which separates it into the surname and rest of name) and then further split the rest of name on period (which separates it into the honorific and rest of name).
df = pd.concat([train_df, test_df])
df.Name.str.split(', ', expand=True)[1].str.split('.', expand=True)[0].value_counts()
# Output
# Mr 757
# Miss 260
# Mrs 197
# Master 61
# Rev 8
# Dr 8
# Col 4
# Mlle 2
# Major 2
# Ms 2
# Lady 1
# Sir 1
# Mme 1
# Don 1
# Capt 1
# the Countess 1
# Jonkheer 1
# Dona 1There are a lot of different honorifics on the ship but after some googling, I have figured out what honorific corresponds to what. For example, Mme and Dona are variations of Mrs while Don is a variation of Mr. Replace all these exotic honorifics with their standard counterparts to group them better.
There are also some honorifics which cannot be determined as any of the standard ones - for example Dr, Rev and Col. Group these rare honorifics into one category called Other.
Finally, extract the surname from the names as well and drop both Cabin for having too many missing values and Name now that we have extracted all meaningful information from it.
def clean(df):
df.drop(['Cabin'], axis=1, inplace=True)
df['Surname'] = df.Name.str.split(', ', expand=True)[0]
df['Honorific'] = df.Name.str.split(', ', expand=True)[1].str.split('.', expand=True)[0]
df.drop(['Name'], axis=1, inplace=True)
for x in ['Mlle', 'Ms']:
df.Honorific = df.Honorific.replace(x, 'Miss')
for x in ['Lady', 'Mme', 'the Countess', 'Dona']:
df.Honorific = df.Honorific.replace(x, 'Mrs')
for x in ['Sir', 'Don']:
df.Honorific = df.Honorific.replace(x, 'Mr')
for x in ['Dr', 'Rev', 'Major', 'Col', 'Capt']:
df.Honorific = df.Honorific.replace(x, 'Other')
df.Honorific = df.Honorific.replace('Jonkheer', 'Master')
return df
train_df = clean(train_df)
test_df = clean(test_df) -
I am not happy with the unknown Other honorific. Let's look at how many males and females are in it and if we can merge them with the standard honorifics using that information.
df = pd.concat([train_df, test_df])
df[df.Honorific == 'Other'].Sex.value_counts()
# Output
# male 22
# female 1There is only one female with the Other honorific. She must be either a Mrs or a Miss. Let's look at her stats.
df[(df.Honorific == 'Other') & (df.Sex == 'female')]
# Output
# Survived Pclass Sex Age SibSp Parch Ticket Fare Embarked Surname Honorific
# 1.0 1 female 49.0 0 0 17465 25.9292 S Leader Othersns.catplot(data=df, x='Honorific', y='Age', kind='box')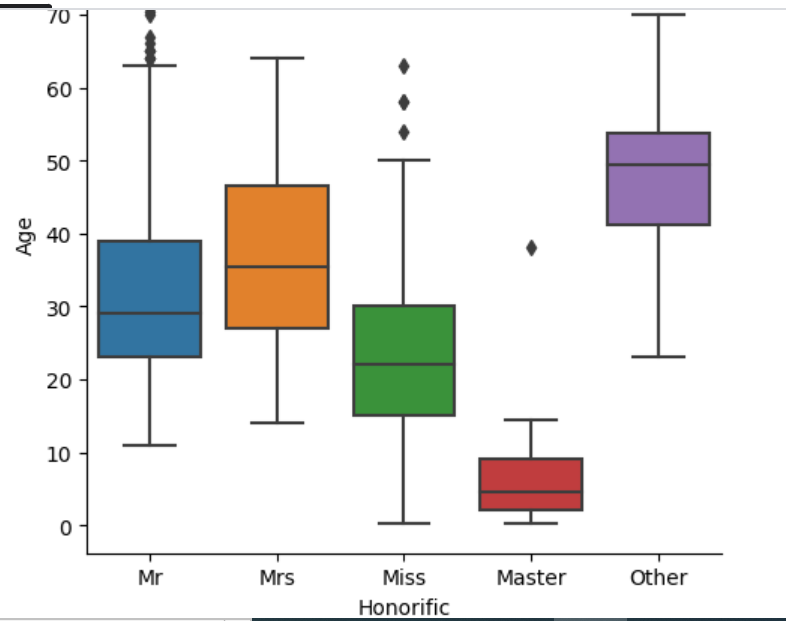
She is 49 years old so she is probably Mrs (we can see from the plot how different honorifics are in different age ranges).
By looking at the Age of males with Other honorific, we can deduce whether they should be Mr or Master.
df[(df.Honorific == 'Other') & (df.Sex == 'male')].Age
# Output
# PassengerId
# 150 42.0
# 151 51.0
# 246 44.0
# 250 54.0
# 318 54.0
# 399 23.0
# 450 52.0
# 537 45.0
# 627 57.0
# 633 32.0
# 648 56.0
# 661 50.0
# 695 60.0
# 746 70.0
# 767 NaN
# 849 28.0
# 887 27.0
# 1023 53.0
# 1041 30.0
# 1056 41.0
# 1094 47.0
# 1185 53.0All males with Other honorific are in the age range of 23 to 70 indicating they are all Mr (from the plot above).
Replace the Other honorifics with appropriate values that we have deduced.
train_df.loc[train_df.index == 797, 'Honorific'] = train_df.loc[train_df.index == 797, 'Honorific'].replace('Other', 'Mrs')
train_df.Honorific = train_df.Honorific.replace('Other', 'Mr')
test_df.Honorific = test_df.Honorific.replace('Other', 'Mr') -
Now let's look at the Surname feature. From the first five rows (and from intuition as well) it looks like there are a lot of different surnames on the ship. We will either have to do Target Encoding for this feature or drop it if there are too many surnames in the test data that are not present in the train data.
Find the number of surnames present in train data but not in test data, in test data but not in train data and in both train and test data.
print('Only train: ', len(set(train_df.Surname.unique()).difference(set(test_df.Surname.unique()))))
print('Only test: ', len(set(test_df.Surname.unique()).difference(set(train_df.Surname.unique()))))
print('Both train and test: ', len(set(train_df.Surname.unique()).intersection(set(test_df.Surname.unique()))))
# Output
# Only train: 523
# Only test: 208
# Both train and test: 144We can see there are a lot of surnames in the test data that are not in the train data and very few surnames in both train and test. This means Target Encoding will not work. Drop the feature.
train_df.drop(['Surname'], axis=1, inplace=True)
test_df.drop(['Surname'], axis=1, inplace=True)